


《计算机应用》唯一官方网站 ›› 2024, Vol. 44 ›› Issue (1): 32-38.DOI: 10.11772/j.issn.1001-9081.2022081260
收稿日期:2022-08-25
修回日期:2022-12-14
接受日期:2023-01-31
发布日期:2023-02-28
出版日期:2024-01-10
通讯作者:
陈景强
作者简介:黄懿蕊(1997—),女,江苏南通人,硕士研究生,主要研究方向:跨模态检索;基金资助:
Yirui HUANG1, Junwei LUO2, Jingqiang CHEN1,3( )
)
Received:2022-08-25
Revised:2022-12-14
Accepted:2023-01-31
Online:2023-02-28
Published:2024-01-10
Contact:
Jingqiang CHEN
About author:HUANG Yirui, born in 1997, M. S. candidate. Her research interests include cross-modal retrieval.Supported by:摘要:
社交媒体网站上使用GIF(Graphics Interchange Format)作为消息的回复相当普遍。但目前大多方法针对问题“如何选择一个合适的GIF回复消息”,没有很好地利用社交媒体上的GIF附属标记信息。为此,提出基于对比学习和GIF标记的多模态对话回复检索(CoTa-MMD)方法,将标记信息整合到检索过程中。具体来说就是使用标记作为中间变量,文本→GIF的检索就被转换为文本→GIF标记→GIF的检索,采用对比学习算法学习模态表示,并利用全概率公式计算检索概率。与直接的文本图像检索相比,引入的过渡标记降低了不同模态的异质性导致的检索难度。实验结果表明,CoTa-MMD模型相较于深度监督的跨模态检索(DSCMR)模型,在PEPE-56多模态对话数据集和Taiwan多模态对话数据集上文本图像检索任务的召回率之和分别提升了0.33个百分点和4.21个百分点。
中图分类号:
黄懿蕊, 罗俊玮, 陈景强. 基于对比学习和GIF标记的多模态对话回复检索[J]. 计算机应用, 2024, 44(1): 32-38.
Yirui HUANG, Junwei LUO, Jingqiang CHEN. Multi-modal dialog reply retrieval based on contrast learning and GIF tag[J]. Journal of Computer Applications, 2024, 44(1): 32-38.

图1 推特用户选择GIF回复的典型流程
Fig. 1 Typical flow for Twitter users to select GIF replies
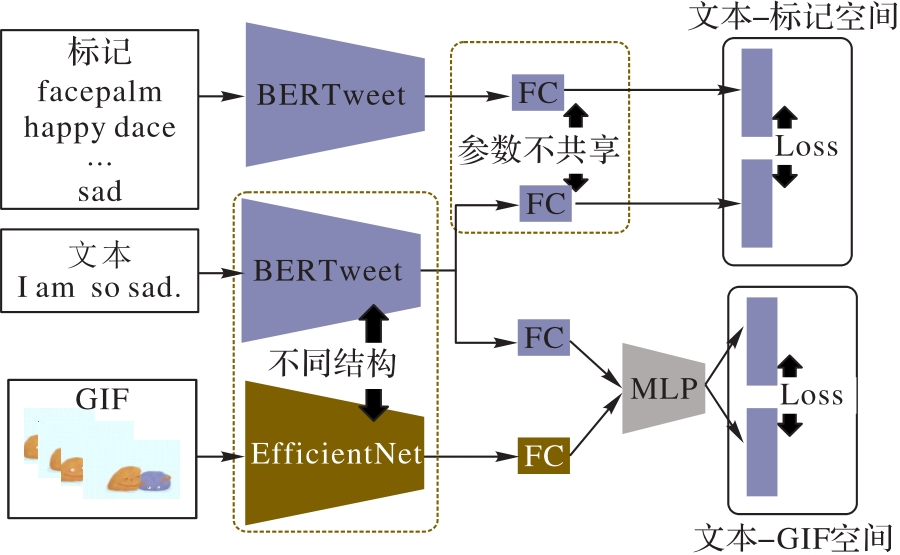
图2 CoTa-MMD的框架
Fig. 2 Framework of CoTa-MMD
| 模型 | Recall@1 | Recall@5 | Recall@10 | rsum |
|---|---|---|---|---|
| PVSE | 0.005 3 | 0.010 6 | 0.019 5 | 0.035 4 |
| PCME(k=5) | 0.007 1 | 0.023 1 | 0.040 8 | 0.071 0 |
| PCME(k=7) | 0.008 9 | 0.033 7 | 0.049 7 | 0.092 3 |
| CLIP-variant | 0.001 8 | 0.008 9 | 0.017 8 | 0.028 5 |
| crossCLR | 0.008 9 | 0.021 3 | 0.039 1 | 0.069 3 |
| DSCMR | 0.003 6 | 0.023 0 | 0.046 0 | 0.072 6 |
| 本文模型 | 0.035 5 | 0.136 7 | 0.234 3 | 0.406 5 |
表1 在PEPE-56数据集上的召回率对比结果 ( %)
Tab. 1 Recall comparison results on PEPE-56 dataset
| 模型 | Recall@1 | Recall@5 | Recall@10 | rsum |
|---|---|---|---|---|
| PVSE | 0.005 3 | 0.010 6 | 0.019 5 | 0.035 4 |
| PCME(k=5) | 0.007 1 | 0.023 1 | 0.040 8 | 0.071 0 |
| PCME(k=7) | 0.008 9 | 0.033 7 | 0.049 7 | 0.092 3 |
| CLIP-variant | 0.001 8 | 0.008 9 | 0.017 8 | 0.028 5 |
| crossCLR | 0.008 9 | 0.021 3 | 0.039 1 | 0.069 3 |
| DSCMR | 0.003 6 | 0.023 0 | 0.046 0 | 0.072 6 |
| 本文模型 | 0.035 5 | 0.136 7 | 0.234 3 | 0.406 5 |
| 模型 | Recall@1 | Recall@5 | Recall@10 | rsum |
|---|---|---|---|---|
| PVSE | 0.104 0 | 0.319 9 | 0.519 8 | 0.943 7 |
| PCME(k=5) | 0.207 9 | 0.467 8 | 0.831 6 | 1.507 3 |
| PCME(k=7) | 0.259 9 | 0.519 8 | 0.883 6 | 1.663 3 |
| CLIP-variant | 0.104 0 | 0.623 7 | 1.090 5 | 1.818 2 |
| crossCLR | 0.052 0 | 0.259 9 | 0.519 8 | 0.831 7 |
| DSCMR | 0.311 9 | 0.571 7 | 1.299 4 | 2.183 0 |
| 本文模型 | 0.519 8 | 2.183 0 | 3.690 2 | 6.393 0 |
表2 在Taiwan数据集上的召回率对比结果 ( %)
Tab. 2 Recall comparison results on Taiwan dataset
| 模型 | Recall@1 | Recall@5 | Recall@10 | rsum |
|---|---|---|---|---|
| PVSE | 0.104 0 | 0.319 9 | 0.519 8 | 0.943 7 |
| PCME(k=5) | 0.207 9 | 0.467 8 | 0.831 6 | 1.507 3 |
| PCME(k=7) | 0.259 9 | 0.519 8 | 0.883 6 | 1.663 3 |
| CLIP-variant | 0.104 0 | 0.623 7 | 1.090 5 | 1.818 2 |
| crossCLR | 0.052 0 | 0.259 9 | 0.519 8 | 0.831 7 |
| DSCMR | 0.311 9 | 0.571 7 | 1.299 4 | 2.183 0 |
| 本文模型 | 0.519 8 | 2.183 0 | 3.690 2 | 6.393 0 |
| 模型 | Recall@1 | Recall@5 | Recall@10 | rsum |
|---|---|---|---|---|
| 0.311 9 | 1.247 4 | 2.234 9 | 3.794 2 | |
| 0.519 8 | 1.923 1 | 3.118 5 | 5.561 4 | |
| 0.467 8 | 1.715 2 | 3.534 3 | 5.717 3 | |
| 0.259 8 | 1.247 4 | 3.014 6 | 4.521 8 | |
| 0.519 8 | 2.183 0 | 3.690 2 | 6.393 0 |
表3 在Taiwan数据集上的消融实验结果 ( %)
Tab. 3 Ablation experimental results on Taiwan dataset
| 模型 | Recall@1 | Recall@5 | Recall@10 | rsum |
|---|---|---|---|---|
| 0.311 9 | 1.247 4 | 2.234 9 | 3.794 2 | |
| 0.519 8 | 1.923 1 | 3.118 5 | 5.561 4 | |
| 0.467 8 | 1.715 2 | 3.534 3 | 5.717 3 | |
| 0.259 8 | 1.247 4 | 3.014 6 | 4.521 8 | |
| 0.519 8 | 2.183 0 | 3.690 2 | 6.393 0 |
| GIF标记设置 | Recall@1 | Recall@5 | Recall@10 | rsum |
|---|---|---|---|---|
| 没有标记 | 0.104 0 | 0.623 7 | 1.090 5 | 1.818 2 |
| 真实标记 | 0.467 8 | 1.507 3 | 2.390 8 | 4.365 9 |
| 预测标记概率 | 0.519 8 | 2.183 0 | 3.690 2 | 6.393 0 |
表4 不同标记设置的实验结果 ( %)
Tab. 4 Experimental results of different tag settings
| GIF标记设置 | Recall@1 | Recall@5 | Recall@10 | rsum |
|---|---|---|---|---|
| 没有标记 | 0.104 0 | 0.623 7 | 1.090 5 | 1.818 2 |
| 真实标记 | 0.467 8 | 1.507 3 | 2.390 8 | 4.365 9 |
| 预测标记概率 | 0.519 8 | 2.183 0 | 3.690 2 | 6.393 0 |
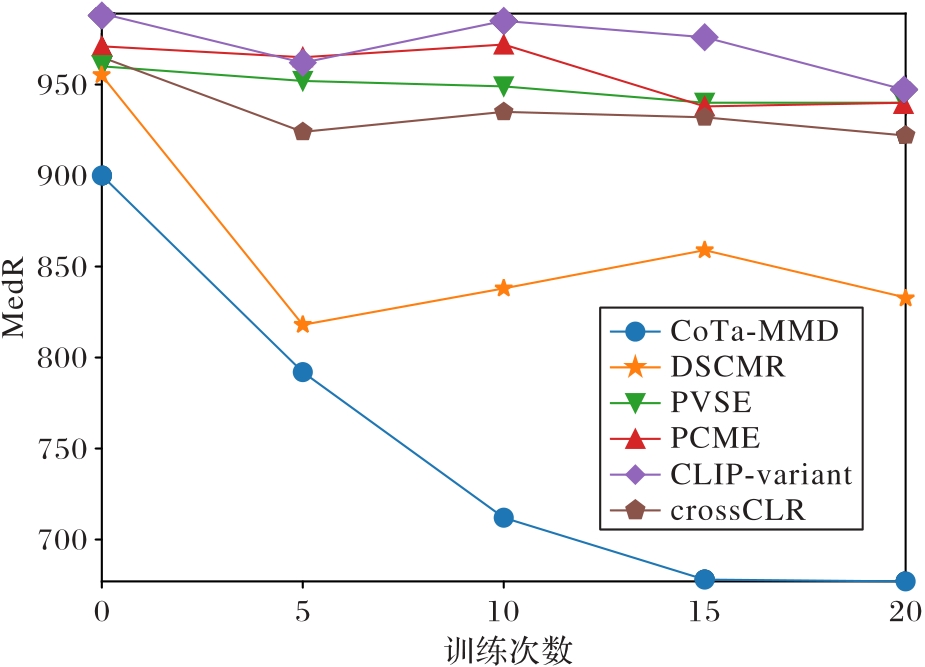
图3 Taiwan数据集不同模型MedR曲线
Fig. 3 MedR curves for different models for Taiwan dataset

图4 不同模型根据文本检索的GIF回复
Fig. 4 GIF replies retrieved according to text by different models
| 1 | SONG Y, SOLEYMANI M. Polysemous visual-semantic embedding for cross-modal retrieval [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1979-1988. 10.1109/cvpr.2019.00208 |
| 2 | WANG X, JURGENS D. An animated picture says at least a thousand words: selecting gif-based replies in multimodal dialog [C]// Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg, PA: Association for Computational Linguistics, 2021: 3228-3257. 10.18653/v1/2021.findings-emnlp.276 |
| 3 | WANG Y, WU F, SONG J, et al. Multi-modal mutual topic reinforce modeling for cross-media retrieval [C]// Proceedings of the 22nd ACM International Conference on Multimedia. New York: ACM, 2014: 307-316. 10.1145/2647868.2654901 |
| 4 | ZHEN L, HU P, WANG X, et al. Deep supervised cross-modal retrieval [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 10386-10395. 10.1109/cvpr.2019.01064 |
| 5 | LI M, LI Y, HUANG S-L, et al. Semantically supervised maximal correlation for cross-modal retrieval [C]// Proceedings of the 2020 IEEE International Conference on Image Processing. Piscataway: IEEE, 2020: 2291-2295. 10.1109/icip40778.2020.9190873 |
| 6 | ZHANG S, XU R, XIONG C, et al. Use all the labels: a hierarchical multi-label contrastive learning framework [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 16639-16648. 10.1109/cvpr52688.2022.01616 |
| 7 | IQBAL J, ALI M. MLSL: Multi-level self-supervised learning for domain adaptation with spatially independent and semantically consistent labeling [C]// Proceedings of the 2020 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 1864-1873. 10.1109/wacv45572.2020.9093626 |
| 8 | BUCCI S, D’INNOCENTE A, TOMMASI T. Tackling partial domain adaptation with self-supervision [C]// Proceedings of the 2019 International Conference on Image Analysis and Processing. Cham: Springer, 2019: 70-81. 10.1007/978-3-030-30645-8_7 |
| 9 | PAN F, SHIN I, RAMEAU F, et al. Unsupervised intra-domain adaptation for semantic segmentation through self-supervision [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3763-3772. 10.1109/cvpr42600.2020.00382 |
| 10 | GIDARIS S, BURSUC A, KOMODAKIS N, et al. Boosting few-shot visual learning with self-supervision [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 8059-8068. 10.1109/iccv.2019.00815 |
| 11 | WANG Y, ZHANG J, LI H, et al. ClusterSCL: Cluster-aware supervised contrastive learning on graphs [C]// Proceedings of the 2022 ACM Web Conference. NewYork: ACM, 2022: 1611-1621. 10.1145/3485447.3512207 |
| 12 | SUN K, LIN Z, ZHU Z. Multi-stage self-supervised learning for graph convolutional networks on graphs with few labeled nodes [J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(4): 5892-5899. 10.1609/aaai.v34i04.6048 |
| 13 | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6077-6086. 10.1109/cvpr.2018.00636 |
| 14 | TENEY D, LIU L, VAN DEN HENGEL A. Graph-structured representations for visual question answering [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3233-3241. 10.1109/cvpr.2017.344 |
| 15 | V-Q NGUYEN, SUGANUMA M, OKATANI T. Efficient attention mechanism for visual dialog that can handle all the interactions between multiple inputs [C]// Proceedings of the 2020 European Conference on Computer Vision. Cham: Springer, 2020: 223-240. 10.1007/978-3-030-58586-0_14 |
| 16 | ZHANG Y, SUN S, GALLEY M, et al. DIALOGPT: Large-scale generative pre-training for conversational response generation [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 270-278. 10.18653/v1/2020.acl-demos.30 |
| 17 | RASIWASIA N, COSTA PEREIRA J, COVIELLO E, et al. A new approach to cross-modal multimedia retrieval [C]// Proceedings of the 18th International Conference on Multimedia. New York: ACM, 2010: 251-260. 10.1145/1873951.1873987 |
| 18 | ANDREW G, ARORA R, BILMES J, et al. Deep canonical correlation analysis [C]// Proceedings of the 30th International Conference on Machine Learning. New York: JMLR.org, 2013: 1247-1255. |
| 19 | GE X, CHEN F, JOSE J M, et al. Structured multi-modal feature embedding and alignment for image-sentence retrieval [C]// Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 5185-5193. 10.1145/3474085.3475634 |
| 20 | DOUGHTY H, SNOEK C G M. How do you do it? Fine-grained action understanding with pseudo-adverbs [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 13822-13832. 10.1109/cvpr52688.2022.01346 |
| 21 | WANG Y, YANG H, QIAN X, et al. Position focused attention network for image-text matching [C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019: 3792-3798. 10.24963/ijcai.2019/526 |
| 22 | 刘长红,曾胜,张斌,等.基于语义关系图的跨模态张量融合网络的图像文本检索[J].计算机应用, 2022, 42(10): 3018-3024. 10.11772/j.issn.1001-9081.2021091622 |
| LIU C H, ZENG S, ZHANG B, et al. Cross-modal tensor fusion network based on semantic relation graph for image-text retrieval [J]. Journal of Computer Applications, 2022, 42(10): 3018-3024. 10.11772/j.issn.1001-9081.2021091622 | |
| 23 | 刘颖,郭莹莹,房杰,等.深度学习跨模态图文检索研究综述[J].计算机科学与探索, 2022, 16(3): 489-511. 10.3778/j.issn.1673-9418.2107076 |
| LIU Y, GUO Y Y, FANG J, et al. Survey of research on deep learning image text cross-modal retrieval [J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(3): 489-511. 10.3778/j.issn.1673-9418.2107076 | |
| 24 | GU J, CAI J, JOTY S, et al. Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7181-7189. 10.1109/cvpr.2018.00750 |
| 25 | REN S, LIN J, ZHAO G, et al. Learning relation alignment for calibrated cross-modal retrieval [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2021: 514-524. 10.18653/v1/2021.acl-long.43 |
| 26 | CHEN H, DING G, LIU X, et al. IMRAM: Iterative matching with recurrent attention memory for cross-modal image-text retrieval [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 12652-12660. 10.1109/cvpr42600.2020.01267 |
| 27 | RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// Proceedings of the 2021 International Conference on Machine Learning. New York: JMLR.org, 2021: 8748-8763. |
| 28 | ZOLFAGHARI M, ZHU Y, GEHLER P, et al. CrossCLR: Cross-modal contrastive learning for multi-modal video representations [C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 1430-1439. 10.1109/iccv48922.2021.00148 |
| 29 | NGUYEN D Q, VU T, NGUYEN A T. BERTweet: A pre-trained language model for English Tweets [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg, PA: Association for Computational Linguistics, 2020: 9-14. 10.18653/v1/2020.emnlp-demos.2 |
| 30 | TAN M, LE Q V. EfficientNet: Rethinking model scaling for convolutional neural networks [C]// Proceedings of the 36TH International Conference on Machine Learning. New York: JMLR.org, 2019: 6105-6114. |
| 31 | KHOSLA P, TETERWAK P, WANG C, et al. Supervised contrastive learning [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2020: 18661-18673. |
| 32 | SHMUELI B, RAY S, KU L-W. Happy dance, slow clap: Using reaction GIFs to predict induced affect on Twitter [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2021: 395-401. 10.18653/v1/2021.acl-short.50 |
| 33 | LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [EB/OL]. [2022-02-19]. . |
| 34 | CHUN S, OH S J, DE REZENDE R S, et al. Probabilistic embeddings for cross-modal retrieval [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 8411-8420. 10.1109/cvpr46437.2021.00831 |
| [1] | 王春雷, 王肖, 刘凯. 多模态知识图谱表示学习综述[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 1-15. |
| [2] | 刘秋杰, 万源, 吴杰. 深度双模态源域对称迁移学习的跨模态检索[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 24-31. |
| [3] | 佟威, 何理扬, 李锐, 黄威, 黄振亚, 刘淇. 基于无监督语义哈希的高效相似题检索模型[J]. 《计算机应用》唯一官方网站, 2024, 44(1): 206-216. |
| [4] | 张琨, 杨丰玉, 钟发, 曾广东, 周世健. 基于混合代码表示的源代码脆弱性检测[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2517-2526. |
| [5] | 王静红, 周志霞, 王辉, 李昊康. 双路自编码器的属性网络表示学习[J]. 《计算机应用》唯一官方网站, 2023, 43(8): 2338-2344. |
| [6] | 谭钰, 王小琴, 蓝如师, 刘振丙, 罗笑南. 基于判别性矩阵分解的多标签跨模态哈希检索[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1349-1354. |
| [7] | 雷景生, 剌凯俊, 杨胜英, 吴怡. 基于上下文语义增强的实体关系联合抽取[J]. 《计算机应用》唯一官方网站, 2023, 43(5): 1438-1444. |
| [8] | 高榕, 沈加伟, 邵雄凯, 吴歆韵. 基于Fastformer和自监督对比学习的实例分割算法[J]. 《计算机应用》唯一官方网站, 2023, 43(4): 1062-1070. |
| [9] | 党伟超, 程炳阳, 高改梅, 刘春霞. 基于对比超图转换器的会话推荐[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3683-3688. |
| [10] | 张安勤, 王小慧. 基于时序异常检测的动力电池安全预警[J]. 《计算机应用》唯一官方网站, 2023, 43(12): 3799-3805. |
| [11] | 富坤, 郝玉涵, 孙明磊, 刘赢华. 基于优化图结构自编码器的网络表示学习[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3054-3061. |
| [12] | 吴明月, 周栋, 赵文玉, 屈薇. 基于流形学习的句向量优化[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3062-3069. |
| [13] | 毕以镇, 马焕, 张长青. 增广模态收益动态评估方法[J]. 《计算机应用》唯一官方网站, 2023, 43(10): 3099-3106. |
| [14] | 杜航原, 郝思聪, 王文剑. 结合图自编码器与聚类的半监督表示学习方法[J]. 《计算机应用》唯一官方网站, 2022, 42(9): 2643-2651. |
| [15] | 周乐, 代婷婷, 李淳, 谢军, 楚博策, 李峰, 张君毅, 刘峤. 基于节点-属性二部图的网络表示学习模型[J]. 《计算机应用》唯一官方网站, 2022, 42(8): 2311-2318. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||